Two cases of Interface fail: Hotmail font meltdown and Gmail vs the Gestaltists.
Ok, let’s look at a real life example of total GUI design fail. Or perhaps, not a total fail, but just bad design that manages to get by because it’s not catastrophic and therefore doesn’t get fixed but instead slows everybody down just a little – which is arguably worse.
I use a Hotmail email account – it’s the same account I opened in 2001, and I keep it because it has been the most constant and unchanging way of getting hold of me ever since. And I am not alone, preliminary research suggests that there are several hundred million other people using this service too. So little inconveniences, multiplied by that many users, well… you get the idea.
So what’s my gripe? Sometimes, emails come with attachments. It’s a pretty common thing to do. So the question is – how do I know there is an attachment with my email and what do I want to do with it when one is there?
Let’s have a look. Here’s an email I just opened with one attachment.

Now… in the screenshot below have a look at how many different ways the application is telling me that there is an attachment present. Four. There are four distinct visual elements all telling me exactly the same thing – this email has an attachment present. Hmmm…
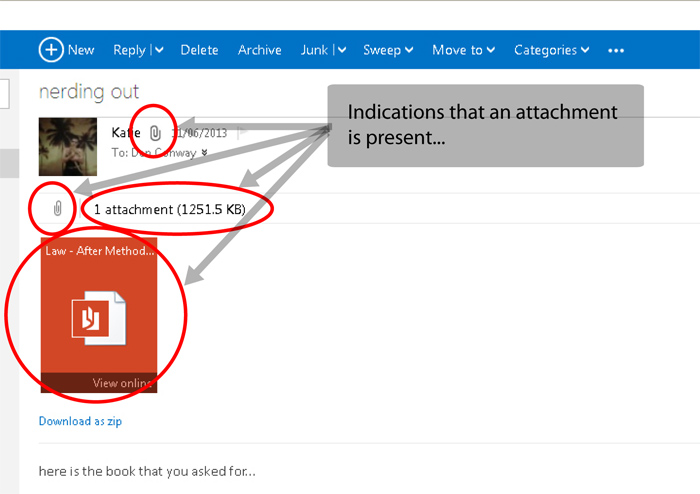
So initially one might think – well that’s ok – the more obvious we make it the better… but unfortunately, this isn’t always the case. There’s a large body of research that suggests that having to process multiple redundant signals actually takes up more cognitive resources than just processing one. This is particularly true when spread across multiple sense modalities. So if you want to tell your user something urgent, having every light on the dashboard flash and sounding an alarm and vibrating the controller may get the point across that something is happening, but may so overload our cognitive mechanism that it becomes difficult to focus on the best action to take.
Whilst that might seem an extreme example, it does suggest an important design guideline (as well as a favourite of the scientific domain), that of parsimony, which in this case might be expressed as ‘don’t do more than necessary to complete the job’. Cutting down the number of indicators used to signal something can also help a little with visual-clutter and make other things easier to find – although admittedly the hotmail screen is already reasonably sparse and does, in fact, include a lot of white-space.
So now that we are aware that we have a file attached to this email, the next question is: what is this file. In the screenshot below three files, all in different formats, are displayed as attached to an email.

From an initial glance one learns the following:
- There are three files attached.
- One of them is a picture.
- The other two seem to be differing file formats.
- The total size of all the attachments together is 632.3Kb.
But what is NOT clear is the following:
- What are the file formats of the two files on the right?
- What is the difference in file names? Is one perhaps named ‘latest’?
- How big are the individual files? In other cases one file might be enormous – and therefore you may want not to download it at home where you have limited bandwidth – whilst the other files might be tiny.
Plus a whole bunch of ancillary data which might be nice such as:
- Date created.
- Date last modified.
- Permissions
- Meta-data
 Furthermore, and while this is as much a design as it is a usability perspective – there are a total of five different font/colour combinations used to display this information. Ugh.
Furthermore, and while this is as much a design as it is a usability perspective – there are a total of five different font/colour combinations used to display this information. Ugh.
So now, let’s say we want to do something with these attachments. And here’s where the real problems in the existing interface present themselves. Have a look at the different font/colour combinations used to show us information about these attachments. Notice that the three bits of text that represent actions – ie: that will do something when clicked – are all presented in completely different visual forms (the bottom three icons as shown above). This is extremely poor design in that it requires the user to actually read each piece of text, and parse different colour/font combinations to try and understand that is possible with each file. Furthermore as you can see above, different options are actually presented for different file types even though you can do the same thing (download, view online) with all of them. This may, however be because certain actions are most common for certain file-types so let’s give the designers the benefit of the doubt here.
But having different options in different font/colours raises further considerations. In the Visual Search paradigm, it has been shown that in certain situations, searching for a target amongst a field of distractors can take place blindingly quickly – in these cases it would appear that our cognitive mechanisms manage to perform a ‘parallel search’ – which would imply that lots and lots of processes are carried out at the same time – therefore being extremely fast. This is also known as the ‘pop-out’ effect. In other cases however, it would seem that a visual search requires us to process each potential target sequentially – which takes much more time. So the question for interaction designers should really be: what features allow parallel searches of potential visual targets? I’ve mentioned this before on this blog, but today I’d like to talk about it in a little more depth.
 Some of the most important research in this field was pioneered by Anne Triesman, who I’m a huge fan of. She proposed a ‘Feature Integration Theory’ which has HUGE implications for visual interface design in that it clearly elucidates the properties that allow our faculties to carry out a parallel rather than serial search. Specifically, Triesman suggested that visual search is carried out in two stages. Firstly a very rough scan of the entire visual scene is carried out that extracts only very basic features. If this is sufficient to identify a target, then the target is immediately identified (which appears to us as being an example of parallel search). If the target is not visually distinct enough then a second scan is done which processes each object sequentially and therefore takes much more time. Furthermore this second phase requires more active attentional resources than the preliminary scan. But this still hasn’t answered the question about exactly what it is that allows a target to be found on the first search, and Triesman’s insight into this question involves the number of features necessary to distinguish a target from its distracters. If only one feature is necessary, such as colour – ie: the target is red and all the distractors are blue, or shape: the target is triangular, all distractors are oval, then the initial scan can reliably find the target. However, when two or more features have to be integrated in order to distinguish between the target and distractors, such as both colour AND shape, then the much more attentionally demanding second phase involving a seemingly sequential process is carried out.
Some of the most important research in this field was pioneered by Anne Triesman, who I’m a huge fan of. She proposed a ‘Feature Integration Theory’ which has HUGE implications for visual interface design in that it clearly elucidates the properties that allow our faculties to carry out a parallel rather than serial search. Specifically, Triesman suggested that visual search is carried out in two stages. Firstly a very rough scan of the entire visual scene is carried out that extracts only very basic features. If this is sufficient to identify a target, then the target is immediately identified (which appears to us as being an example of parallel search). If the target is not visually distinct enough then a second scan is done which processes each object sequentially and therefore takes much more time. Furthermore this second phase requires more active attentional resources than the preliminary scan. But this still hasn’t answered the question about exactly what it is that allows a target to be found on the first search, and Triesman’s insight into this question involves the number of features necessary to distinguish a target from its distracters. If only one feature is necessary, such as colour – ie: the target is red and all the distractors are blue, or shape: the target is triangular, all distractors are oval, then the initial scan can reliably find the target. However, when two or more features have to be integrated in order to distinguish between the target and distractors, such as both colour AND shape, then the much more attentionally demanding second phase involving a seemingly sequential process is carried out.
What a superb insight. Let’s go back to our hotmail example. Every single one of these options requires an entire different visual mode to be entered into to parse meaning from the objects. And furthermore there is nothing (apart from the text – which must then be read) to distinguish between things that DO something and things that are simply information.
What terrible, terrible design.
So the immediate question immediately becomes – how to I download the second two files? And the interface provides no clue as to this. Yes, if you hover over one of the icons a tooltip will appear telling you to click the icon – but up until you actually DO something – there is nothing to suggest that the icon is actually clickable. Yes, I understand that ‘flat’ design is all the rage at the moment and is a necessary reaction to our overuse of skeuomorphism, but really – we need to find some way of communicating that an object is clickable.
So to sum up, the existing design exhibits the following problems:
- Multiple, redundant, and inconsistent signals that an attachment is present.
- Nothing indicates graphically that the icon can be clicked.
- There is no indication of how to download a document.
- Document names are truncated.
- There is nothing (graphic) to distinguish text that is purely informative from text that – when clicked – does something.
- File-types are denoted only by icon shape/colour meaning that one has to know what these shapes/colours mean (did you know burnt orange represented an Adobe pdf?).
- Different types of files display different options even though the same options are available (in most cases) for all file-types.
- Each piece of information and/or clickable object (even when in the same functional category) is in a significantly different colour/font combination making it difficult to parse quickly.
This last point bears just a little bit more thought. Whilst my critique suggests that the existing design does not leverage colour/font to allow simple object identification and instead requires that we read each text label to identify it’s function, I might even go so far as to suggest that using text that is reversed (light on dark background) as well as normal (and for items in the same functional class – in this case ‘actions that can be carried out with the attachment) is actually detrimental to the object recognition process.
There is no body of work that I can find that discusses the efficacy of reversing some words in a field of possible targets. And this is where I present a hypothesis. I suggest that every time the eye needs to switch from a reversed to a non-reversed text it takes some cognitive effort to do so. Which may be a truism – so let us say measurably more cognitive effort than were all the text the same format. If this were true this essentially becomes a task switching problem, for which there is a huge body of data. And what is essentially happening here is that when the switch happens, our cognitive mechanism must be reset in terms of figure/ground priming. Ie: one of the most fundamental and ‘low level’ visual processes, discussed formally for the first time by the Gestaltists in the 1910’s, is determining what is ‘figure’ and what is ‘ground’ is in a visual scene. The classic example of this being the vase/two faces image below.

What you see depends on what you perceive as the ‘figure’ and what you perceive as the ‘ground’. Swapping over from one mode to the other takes some cognitive effort. As does, I would suggest, swapping from parsing text presented with dark letters on a light background to the inverse.
Furthermore, this assumes that we are aware that the target is in the other figure/ground modality. Let me provide an example where I am convinced that the figure ground problem renders information in the other mode essentially invisible unless the user is specifically looking for it. As of about a year ago I also have a gmail account. When I first started using their interface, I found myself, on quite a few occasions, searching for what to click when I wanted to write a new email. And seriously I would hunt the screen – for what seemed subjectively like an age – (perhaps 10 seconds?) which made me frustrated and annoyed until eventually AHAH! There it is! So big and coloured and bright – how the HELL could I have missed it? The ‘Compose’ button.

To which the answer of course is – well because the text was in white – your perceptual mechanism had relayed it to ‘background’ and it was therefore essentially invisible to your search. This is just wild conjecture at this point, but I have been thinking about a nice experimental design that would test this assumption. Perhaps more on this later.
One feature of this perceptual figure/ground mechanism is that it seems almost impossible for us to see, in ambiguous situations such as the wonderful Escher print below, both modes as figure at the same time. Our mechanism seems to require that we discard either one gestalt or the other in order to make sense of the shapes… which means that when looking at one particular set of gestalts, the other is essentially invisible. Try it. You’ll see what I mean. And this of course has enormous implications for GUI design.

I find it astonishing that companies such as Microsoft and Google make such fundamental errors such as this. Despite all the lip-service that these companies pay to ‘user experience’ and interaction design, final products seem sometimes to fly in the face of often totally fundamental cognitive and perceptual principles. It would seem that it is still early days for evidence based interaction design.
Newsome, W. T. (1996). Visual attention: Spotlights, highlights and visual awareness. Current Biology, 6(4), 357-360.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97-136.
Ward, L. M. (1982). Determinants of attention to local and global features of visual forms. Journal of Experimental Psychology: Human Perception and Performance, 8(4), 562-581.
Westerink, J. H. D. M., Tang, H. K., van Gelderen, T., & Westrik, R. (1998). Legibility of video-blended TV menus. Applied Ergonomics, 29(1), 59-65.
 Address: 11 Silva St, Tamarama, Sydney, Australia
Address: 11 Silva St, Tamarama, Sydney, Australia Phone: +61 2 (0) 404 214 889
Phone: +61 2 (0) 404 214 889 Email:
Email: 
Recent Comments